
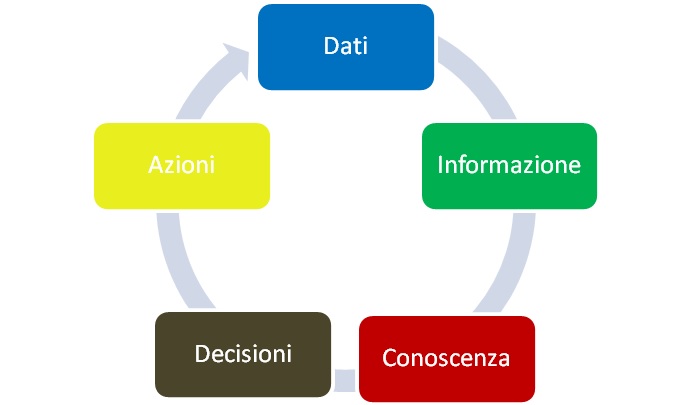
La catena del valore dell’informazione, così come descritta da Abbasi et al. (2016), è schematicamente illustrata in figura 1: dato un qualsiasi fenomeno, la disponibilità di dati, raccolti in maniera organizzata e opportunamente elaborati, genera informazione che, a sua volta, sottoposta al vaglio critico produce conoscenza in base alla quale sono prese opportune decisioni che comportano azioni che a loro volta generano ulteriori dati.
Figura 1 – La catena del valore dell’informazione.
L’ingresso dell’umanità nell’era dell’iperinformazione rischia di minare in profondità questo circuito virtuoso. In che modo? Ne abbiamo parlato al 48° Congresso di Buiatria, celebrato a Montichiari lo scorso settembre; questa è una breve report su quanto esposto in quella sede.
L’età dell’iperinformazione
Che cosa è l’iperinformazione? E’ il neologismo con cui si indica l’enorme mole di dati oggi disponibili (big data) che si sposa con la sempre maggiore facilità di comunicazione fra i soggetti (internet e social network) e l’inflazione della produzione scientifica. Se vogliamo dare un’idea della produzione odierna di dati, osserviamo che attualmente, ogni giorno, l’umanità produce 2,5 quintilioni di dati (il 90% dei dati sono stati generati negli ultimi 2 anni), equivalenti alla metà di quella prodotta dall’origine della civiltà al 2003 (E. Schidt, CEO di Google). Anche la comunicazione opera in modo impressionante, con 500 milioni di tweet e 70 milioni di foto inviate giornalmente e 4 miliardi di video già residenti su Facebook (Grossman, Time Magazine, 2015). Oltre ad una straordinaria risorsa, big data e social possono rappresentare un pericolo in quanto distruttori della catena del valore dell’informazione e amplificatori di messaggi distorti. In questo articolo dimostreremo che: a) la disintermediazione dei social media alimenta teorie errate a scapito di informazioni corrette; b) la pervasività dei social media può provocare dannose distorsioni nell’opinione pubblica (e di riflesso sugli scienziati); c) i big data e i social NON possono e non devono essere distruttivi della catena del valore dell’informazione e del metodo scientifico.
Verificheremo anche in che modo I big data pongono problemi etici all’agricoltura e possono rappresentare una risorsa importante per la zootecnia.
Cosa succede all’informazione? Social e bufale….
L’informazione sta cambiando rapidamente connotati. L’avvento dei social net comporta che la produzione e il consumo dei contenuti sono fortemente disintermediati nel senso che chiunque è in grado di pubblicare ciò che crede senza una verifica sulla fondatezza o sostenibilità di quanto pubblicato. Si ha perciò l’impressione che iperinformazione e disinformazione convivano. Come vedremo sono entrambe facce della stessa medaglia. Il propagarsi di notizie infondate via social è ritenuta dal World Economic Forum (2013) uno dei pericoli maggiori per il prossimo futuro: “The global risk of massive digital misinformation sits at the centre of a constellation of technological and geopolitical risks ranging from terrorism to cyber attacks and the failure of global governance”.
Dai lavori di alcuni ricercatori, pubblicati su diverse riviste scientifiche, è emerso un quadro sconcertante e preoccupante che riassumeremo brevemente. Il gruppo di lavoro di Walter Quattrociocchi, dell’IMT Alti Studi di Lucca, ha esplorato cosa avviene nel mondo dei cosiddetti social network con l’impiego di metodi quantitativi.
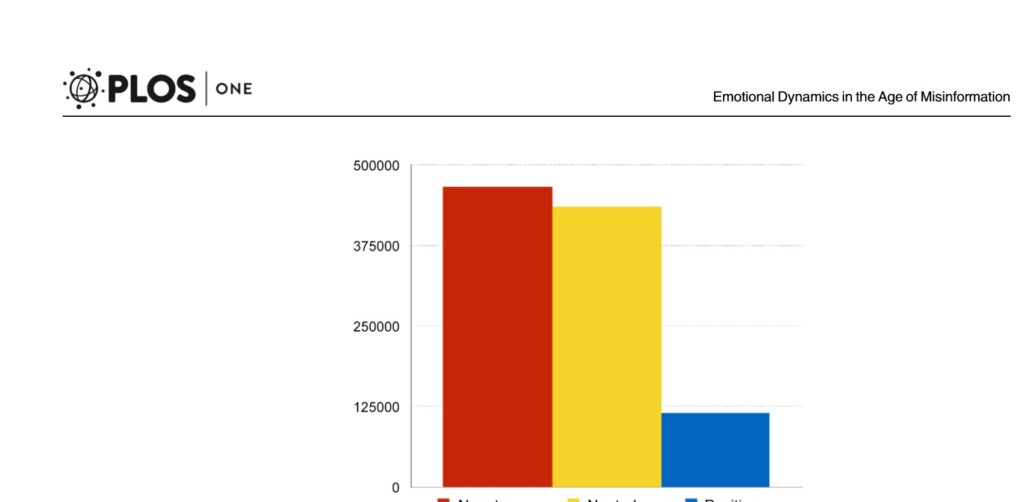
Diversi studi, condotti principalmente in ambito della cosiddetta neuro-economia, dimostrano che l’essere umano, in un contesto informativo non filtrato, non è razionale e prende per buono tutto ciò che più gli aggrada (confirmation bias). Il web ha facilitato l’interconnessione e orientato l’accesso ai contenuti: si sono così formate delle Echo Chambers, comunità che condividono interessi e selezionano informazioni secondo una narrazione del mondo condivisa, all’interno delle quali i messaggi rimbalzano e si rinforzano. Un’analisi quantitativa condotta sui social in Italia è durata 4 anni (Zollo et al., 2015). Sono state selezionati 2 cluster di utenti, una di individui esposti a news scientifiche, l’altra a notizie alternative (prive di fonte). L’analisi ha dimostrato, come riportato in figura 2, che i commenti negativi (e quelli neutri) sono di gran lunga superiori a quelli positivi, denotando una prevalenza dell’umore sfavorevole.
Figura 2 – Nel mondo dei social i commenti negativi (in rosso) prevalgono di gran lunga su quelli positivi (in blu; i neutri in giallo; Zollo et al., 2015)
In un altro lavoro (Bessi et al., 2015b), i ricercatori hanno rilevato che i gruppi di utenti tendono a polarizzarsi fra science oriented e cospiracy (cospirazione nel senso che coloro che danno credito a notizie infondate sono portati a sostenere teorie di complotto per giustificare fatti che potrebbero essere altrimenti spiegabili) in modo che i commenti negativi prevalgono decisamente nel secondo rispetto al primo gruppo. L’aumento dei contatti (le volte che una notizia è rimbalzata da un utente all’altro) tende a peggiorare l’umore dei social, ma questo accade in entrambi i gruppi.
Il gruppo di Quattrociocci si è poi preso la briga di verificare le modalità con cui le notizie fondate e quelle infondate di propagano nel web ( Del Vicario et al., 2016) e hanno trovato che, sebbene i due gruppi mostrino comportamento di consumo simile, le notizie rimbalzano nelle Echo Chambers e si diffondono in maniera più persistente per i fatti non verificati rispetto a quelli di fonte scientifica. Infine, sempre Bessi et al., in un altro lavoro (2015), rilevano che i gruppi tendono a suddividersi in quattro aree di interesse, Geopolitica, Dieta, Ambiente e Salute e che i soggetti più attivi sono quelli che si connettono più facilmente alle altre aree di interesse.
Dagli studi citati emerge che i social possono essere distruttivi della catena del valore dell’informazione in quanto:
1. favoriscono false teorie rispetto a fatti certificati (teorie complottiste vs paradigmi scientifici);
2. rinforzano segnali umorali irrazionali rispetto ad analisi razionali;
3. indeboliscono la fiducia pubblica nei confronti della scienza.
In definitiva, il pericolo è il deragliamento della informazione di origine controllata (media.DOC) su quella non controllata di blog e social (media.SPAM), con la conseguenza di orientare l’opinione pubblica su teorie antiscientifiche capaci di influenzare i cittadini e conseguentemente di screditare la comunità scientifica.
I big data: opportunità e pericoli
Big data è un neologismo che è, con grande successo, entrato di recente nell’uso corrente. Anche se non esiste una definizione “matematica” di big data, gli informatici (Abbasi et al., 2016) sono concordi nell’individuarli attraverso 4 caratteristiche (dette le 4 V): volume, varietà, veridicità e velocità. Vediamole.
a) Volume. Se fino a poco tempo fa la nostra misura dell’entità dell’informazione è stata in Megabyte, la quantità di dati oggi disponibile ha messo in uso termini quali Terabyte, Petabyte ed Exabyte. Teniamo conto che, per avere la dimensione corretta di cosa trattiamo, se un byte è un granello di sabbia, un Megabyte è 1 cucchiaino di sabbia, 1 Terabyte una scatola di sabbia (2 piedi x 1 pollice), un Petabyte una spiaggia lunga 1 miglio e un Exabyte è una spiaggia dal Maine al N. Carolina! Con queste dimensioni in mente, teniamo conto che molte companies USA hanno oggi più di 100 Terabyte di dati stoccati e che i dati sanitari conservati nel mondo al 2011 erano già pari a 150 Exabyte.
b) Velocità. Il ritmo di produzione di dati aumenta in maniera iperbolica. Ad esempio, il New York Stock Exchange, cattura 1 Terabyte di informazioni al giorno, WalMart raccoglie 2,5 Petabytes di transazioni dei clienti ogni ora e ogni giorno si registrano oltre 5 miliardi di domande sui motori di ricerca.
c) Varietà. Attualmente sono on line migliaia di dispositivi differenti che raccolgono e conservano dati. Per citare i più conosciuti canali, ogni ora sono scambiate 240 milioni di email, Facebook raccoglie 3,5 milioni di interazioni, Google 4 miliari di ricerche, Whatsapp 59 miliardi di messaggi.
d) Veridicità. Il principale problema dell’effluvio di informazioni che ci sommerge è la fiducia che riponiamo in loro. Una recente indagine ha verificato che 1 operatore di business su 3 non crede ai dati che impiega e che il 20% di quanto circola sul web è spam. Il costo stimato per gli USA della cattiva qualità dei dati ammonta a 1,3 triliardi di dollari all’anno.
Gli editors della rivista Journal of the Association for Information Systems (Abbasi et al, 2016) ritengono che i big data siano distruttivi della catena del valore dell’informazione in quanto nel mondo dell’informatica stanno entrando nuovi players che portano nuovi processi, vi è un amalgama di tecnologie in “piattaforme” e di processi entro “pipelilnes” nella fase di derivazione della conoscenza, si osserva un maggiore ricorso a data scientist o analyst per supportare decisioni di tipo self-service o real-time a scapito della derivazione della conoscenza da dato
Calude e Longo (2016) si domandano poi se i big data siano distruttivi del metodo scientifico. I due ricercatori partono dall’affermazione di C. Anderson, pubblicata su Wired Magazine nel 2008, secondo il quale “with enough data, the numbers speak for themselves” per cui i big data rendono il metodo scientifico obsoleto. Poiché nel mondo della ricerca è nota la massima di Box (Tutti i modelli sono sbagliati, ma alcuni sono utili), Anderson ribalta il concetto affermando che ora i modelli sono veramente tutti inutili poiché si può avere sempre più successo senza loro: correlazioni trovate in immensi data-base possono sostituire l’analisi di significato tipica della scienza e sostituirsi ad essa nella derivazione della conoscenza nella catena dell’informazione. Se però la distruzione del metodo scientifico si basa sul potere delle correlazioni trovate in smisurate raccolte di dati, Calude e Longo rilevano la fallacia di tale affermazione. Infatti, tenuto conto che una correlazione è essenzialmente una coincidenza, rappresenta cose che avvengono insieme, che le correlazioni sono utili per il loro potere predittivo e che molte conoscenze scientifiche derivano dall’ osservazione di correlazioni contro intuitive, questi strumenti di analisi statistici mostrano i seguenti limiti:
1. le correlazioni non spiegano perché due variabili sono legate;
2. non c’è via per evidenziare una correlazione spuria se non attraverso una teoria (i modelli buttati fuori dalla porta rientrano dalla finestra);
3. la teoria Egodica e il teorema di Ramsey dimostrano che in grandi data-set si realizzano correlazioni spurie proporzionali alla dimensione dell’insieme numerico;
4. troppe informazioni tendono a comportarsi come poche informazioni: vi è difficoltà a trarne un senso.
Possiamo perciò concludere che (fortunatamente) i big data non sono in grado di distruggere il metodo scientifico. Infatti, in assenza di teorie i dati mancano di ordine, senso e significato, le teorie senza dati (quali quelle che circolano nei social) sono vuote, i dati senza teoria sono ciechi. Tuttavia, i big data possono rappresentare un aiuto agli scienziati per riconsiderare la natura delle teorie scientifiche in un mondo di abbondanza di informazioni.
Big data e agricoltura, un problema etico
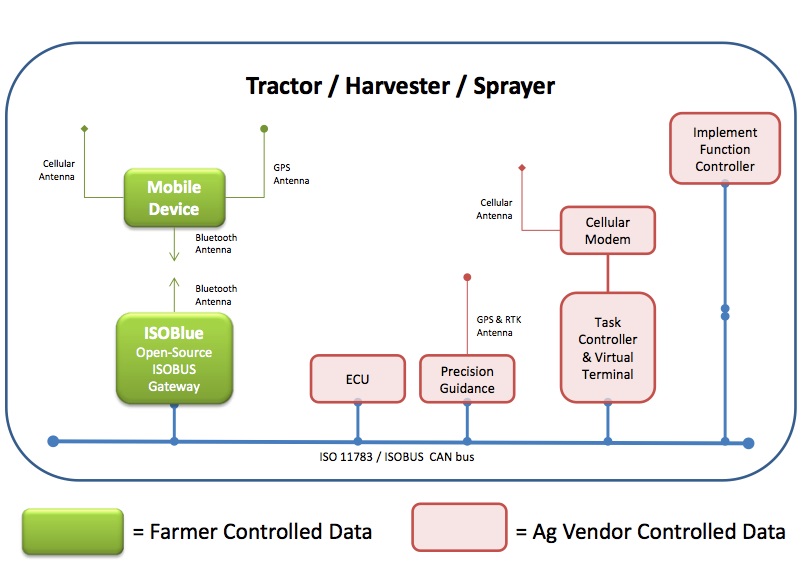
La ricercatrice californiana Isablel Carbonell (2016) ha indagato sui problemi etici che la nascente industria dei big data pone all’agricoltura. Carbonell osserva che le agrobusiness companies sono interessate ai big data per la costruzione di modelli di gestione riguardanti ogni aspetto delle imprese agricole. Per questo motivo la Monsanto, recentemente fusa alla Bayer, ha acquistato la Climate corp per 930 MUSD, azienda che produce modelli su big data per trattamenti e previsioni produttive, tenuto conto che i big data hanno immenso valore per le speculazioni (futures di mais, soia e grano). Dal canto loro, John Deere e General Motor hanno messo il copyright sui software dei macchinari da loro prodotti: d’ora in avanti gli agricoltori non potranno più riparare o modificare i loro macchinari senza rivolgersi a meccanici autorizzati i quali avranno accesso esclusivo ai dati custoditi nelle memorie delle macchine. Questa concentrazione dell’informazione mina alla base l’autonomia degli agricoltori. Infatti, le grandi companies si comportano sempre più da data brokers, nel senso che acquisiscono dati da sensori o direttamente dagli agricoltori senza obblighi nei loro confronti. Per far fronte a questo tipo di problemi, occorre una riorganizzazione sociale dell’agricoltura che limiti la proprietà del controllo delle produzioni da parte delle companies detentrici dei big data; è necessario pertanto finanziare open source analytics per rendere utilizzabili i dati a chi li produce. La Pordue University, nello stato dell’Indiana, ha varato il progetto ISO-blue (http://www.isoblue.org/), una piattaforma open data in grado di rendere disponibili agli agricoltori i dati che normalmente sono raccolti e utilizzati dai venditori, come illustrato in figura 3.
Figura 3 – Il diagramma operativo del progetto ISO-blue della Pordue University.
Big data e zootecnia di precisione: una risorsa importante
Con le tecniche di “Precision Agriculture” e di “Precision Livestock Farming (o PLF)” anche in Zootecnica sono recentemente aumentate le tecnologie dell’informazione e comunicazione (ICT) a disposizione degli allevatori, aumentando la loro capacità lavorativa e l’efficienza tecnico-economica dei loro processi decisionali grazie alla disponibilità sul mercato di una moltitudine di supporti decisionali, o “Decision Support System (DSS)”, che si basano sulla raccolta e archiviazione di dati aziendali relativi al processo produttivo e dalla cui elaborazione automatica sono prodotti indicatori utilizzati dall’allevatore per prendere con maggiore sicurezza le scelte quotidiane in stalla. L’esempio diffuso maggiormente e da più tempo negli allevamenti bovini da latte è il sistema di individuazione dei calori delle bovine sulla base della attività fisica. A tal fine sono stati applicati degli attivometri agli animali (con podometro o collare) che scaricano i dati di attività direttamente su computer e indicano all’allevatore le bovine che devono essere fecondate nelle successive 24 ore. Molteplici strumenti sono stati inventati e messi a disposizione degli allevatori negli ultimi decenni, non ultimi i sistemi di misurazione automatica della produzione che includono misure di flusso di mungitura e di conducibilità elettrica del latte, sistemi di monitoraggio della ruminazione, della funzionalità ruminale e dello stress da caldo. Esistono inoltre numerosi altri device capaci di raccogliere informazioni a livello della singola bovina o singolo capo per altre specie zootecniche e riportarli su supporto digitale, spesso consentendo un monitoraggio continuo e in tempo reale degli animali e del loro comportamento visualizzabile in remoto via tablet o PC (http://www.eu-plf.eu). Molteplici esempi della più recente tecnologia disponibile sono riportati nel testo pubblicato dalla Wageningen Academic Publishers che viene aggiornato periodicamente (ultima pubblicazione Halachmi et al., 2015).
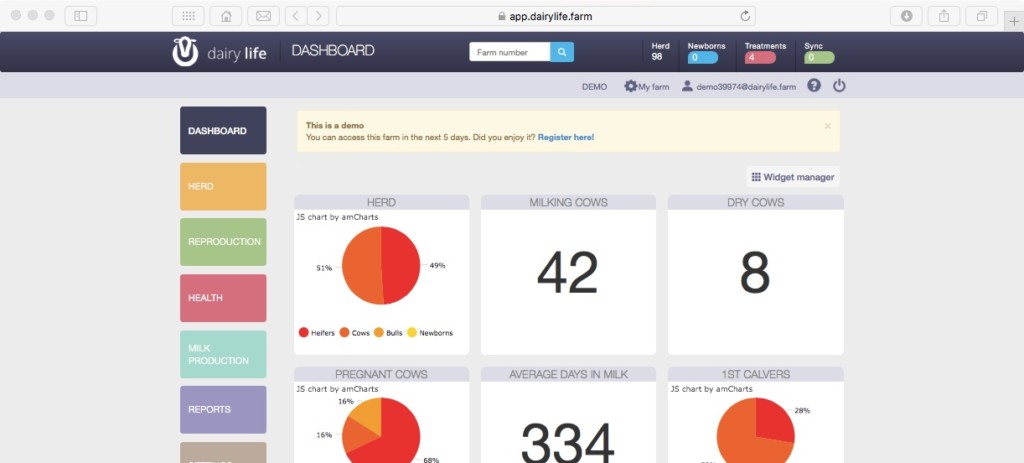
Si prevede un ulteriore aumento di informazioni digitalizzate con la diffusione dell’uso dei software gestionali. Questi strumenti accessibili da tablet e smartphone, consultabili e aggiornabili in tempo reale si sostituiranno alle agende e quaderni di stalla e costituiranno il supporto di consultazione più frequentemente utilizzato dall’allevatore per l’ottimizzazione della gestione della stalla e del proprio tempo. Un esempio recentemente immesso sul mercato è il software Dairy Life, un applicativo gestionale per allevamenti bovini che lavora in cloud, su piattaforme online, capace di:
– archiviare l’anagrafica aziendale e le immagini dei capi,
– supportare la gestione riproduttiva e il piano degli accoppiamenti,
– registrare i trattamenti sanitari e le note delle visite veterinarie (incluse le variazioni dell’armadietto del farmaco),
– collegarsi con altri device presenti in sala di mungitura per la registrazione della produzione del latte,
– elaborare statistiche degli eventi di stalla consultabili in ogni momento e, soprattutto, generare promemoria per le attività da svolgere sugli animali (trattamenti, fecondazioni etc) da inviare all’allevatore o ai suoi collaboratori in tempo reale (Figura 4).
Figura 4. Dashboard DEMO del software Dairy life. (Video: https://youtu.be/q891fXRwW0s)
Alla mole di informazioni raccolta in stalla, dall’allevatore o automaticamente, si aggiungono le informazioni fenotipiche raccolte in specifico dalla associazioni di allevatori per i piani di miglioramento genetico e le informazioni di biologia molecolare provenienti dalle analisi genetiche di genotipizzazione degli animali. Questo tipo di informazioni, codificate e non codificate, costituiscono una fonte informativa utilizzata in maniera parziale ma con ulteriori potenziali per utilizzazioni future con l’avanzare delle scoperte negli studi genomici.
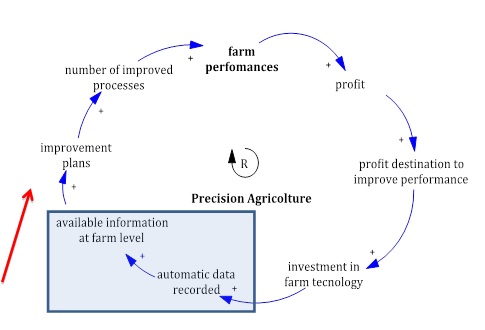
In un nostro lavoro (Atzori et al., 2013) dimostriamo come la corretta gestione dei processi aziendali consente di incrementare le performance aziendali e generare profitti (Figura 5). Seguendo le frecce si può osservare che parte di questi profitti sono destinati a investimenti tecnologici per il supporto decisionale. Questi non sono altro che strumenti capaci di registrare automaticamente informazioni e generare big data. La disponibilità di informazioni e l’elaborazione automatica dei report è oggi alla base del miglioramento della qualità organizzativa degli allevamenti e la conseguente capacità di generare ulteriori profitti dagli investimenti eseguiti. La freccia rossa indica un pericoloso “collo di bottiglia” causato dal gap informativo. La capacità di migliorare la gestione a partire dalle informazioni disponibili è proporzionale alla capacità di comprensione ed elaborazione dei dati che dipende a sua volta dalla conoscenza dei fenomeni
Le fonti informative installate presso gli allevamenti, messe a disposizione in reti condivise, costituiscono il principale aggregato futuro di big data in agricoltura e zootecnia. Il paradigma dell’agricoltura e della zootecnica di precisione funziona solo se supportato dalla corretta informazione. Infatti, avere a disposizione tecnologia non significa riuscire a ottimizzarne l’uso. La sottoutilizzazione e la errata interpretazione delle informazioni provenienti da tecnologie informatiche e supporti decisionali porta elevate perdite economiche (Bewley, 2012). Generalmente si registrano elevate adozioni di tecnologia ma una loro bassa utilizzazione, In pratica le ditte propongono agli allevatori, che le acquistano, tecnologia informatica sempre più potente e sofisticata, ma le potenzialità informative sono trasferite solo parzialmente al settore e sono poco utilizzate per la gestione. La disponibilità di dati è fortemente in crescita anche in zootecnia e la sfida è da intendersi aperta per la comprensione delle informazioni e dei messaggi che dai dati possono essere messi a disposizione della efficienza degli allevamenti e della professionalità degli allevatori e dei tecnici.
Figura 5. Circuito di retroalimentazione o feedback loop della agricoltura e zootecnia di precisione (Atzori et al., 2013).
Conclusioni
L’era della iperinformazione rischia di deragliare in quella della grande ignoranza. La potenza dei social nel diffondere notizie infondate e quella dei big data nel distruggere il metodo scientifico rappresentano un serio pericolo per i sistemi umani basati sulla conoscenza. Agricoltura e zootecnia non sfuggono a questo rischio e, se inconsapevoli, gli attori della filiera possono subire sempre più la dittatura dei proprietari dei dati senza avere strumenti di comunicazione adeguati. Soltanto riportando il metodo scientifico al centro dell’attenzione, quale strumento in grado di produrre conoscenza certificabile e rintracciabile, si potrà arginare la deriva della disinformazione. La zootecnia di precisione è una grande opportunità, ma soltanto se le decisioni non saranno espropriate agli allevatori e questi saranno sempre in gradi di capire cosa dovranno fare e perché prima di procedere alle loro scelte aziendali.
Letteratura citata:
Abbasi Ahmed, Sarker McIntire, Roger H. L. Chiang. 2016. Big Data Research in Information Systems: Toward an Inclusive Research Agenda. Journal of the Association for Information Systems, 17: 1 – 33.
Atzori A.S., Tedeschi L.O., Armenia S., 2013. Farmer Education Enables Precision Farming of Dairy Operations. Proceedings of the International Conference of the System Dynamics Society, July 21 to 25, 2013, Cambridge, MA, USA
Bessi Alessandro, Fabiana Zollo, Michela Del Vicario, Antonio Scala, Guido Caldarelli, Walter Quattrociocchi 2015a. Trend of Narratives in the Age of Misinformation. PLOSONE- DOI:10.1371/journal.pone.0134641 : 1/16
Bessi Alessandro, Mauro Coletto, George Alexandru Davidescu, Antonio Scala, Guido Caldarelli, WalterQuattrociocchi. 2015b. Science vs Conspiracy: CollectiveNarratives in the Age of Misinformation. PLOSONE. DOI:10.1371/journal.pone.0118093: 1-17
Bewley, J.M., 2012. How precision dairy technologies can change your world. Penn State dairy cattle nutrition workshop. November 12-14 Grantville, PA. 65-74.
Calude Cristian S., Giuseppe Longo. 2016. The Deluge of Spurious Correlations in Big Data. Found Sci DOI 10.1007/s10699-016-9489-4: 1-18.
Carbonell Isabelle M. 2016. The ethics of big data in big agriculture. Internet Policy Review , 5(1). DOI: 10.14763/2016.1.405: 1- 13.
Del Vicario Michela, Alessandro Bessi, Fabiana Zollo, Fabio Petroni, Antonio Scala, Guido Caldarellia,. Eugene Stanley, Walter Quattrociocchi. 2016. The spreading of misinformation online. PNAS, vol. 113, n. 3 www.pnas.org/cgi/doi/10.1073/pnas.1517441113: 554–559.
Halacmi I., 2015. Precision livestock farming applications: Making sense of sensors to support farm management. Ed. Ilan Halachmi. Wagenicangen Academic Publisher, Wageningen, The Netherlands.
Zollo Fabiana, Petra KraljNovak, Michela DelVicario, Alessandro Bessi, Igor Mozetič, Antonio Scala, Guido Caldarelli, Walter Quattrociocchi. 2015. Emotional Dynamics in the Age of Misinformation. PLOSONE. DOI:10.1371/journal.pone.0138740. 1-22
Autori: Giuseppe Pulina e Alberto S. Atzori
Sezione di Scienze Zootecniche, Dipartimento di AGRARIA, Università di Sassari.





Scrivi un commento
Devi accedere, per commentare.